- Published on
Building a Fault-Tolerant Sharded Key-Value Store with Paxos
- Authors

- Name
- Bowen Y
Project Overview
In the context of the University of Washington's CSE 452 course on Distributed Systems, I developed a fault-tolerant, sharded key-value (KV) storage system in Java. This project involved implementing an exactly-once Remote Procedure Call (RPC) mechanism, a primary-backup server architecture utilizing Viewstamped Replication for fault tolerance, and a sophisticated multi-Paxos replica system. The design integrated two-phase commit, two-phase locking, and Paxos replica groups to create a simplified, Spanner-like sharded KV-store system.
Course Context: CSE 452 - Distributed Systems
CSE 452 is a senior-level course at the University of Washington that covers abstractions and implementation techniques for constructing distributed systems. Topics include client-server computing, cloud computing, peer-to-peer systems, and distributed storage systems. The course emphasizes hands-on projects to reinforce concepts such as remote procedure calls, consistency maintenance, fault tolerance, high availability, and scalability.
Implementation Overview
1. Exactly-Once RPC Mechanism and Primary-Backup Server
To ensure reliable communication between clients and servers, I implemented an exactly-once RPC mechanism. This approach guarantees that each RPC is executed precisely once, even in the presence of network failures or retries. The primary-backup server architecture was enhanced using Viewstamped Replication, which provides fault tolerance by maintaining consistency between the primary server and its backups. This setup ensures that the system can recover from failures without data loss or inconsistency.
2. Multi-Paxos Replica System
Building upon the primary-backup architecture, I designed a multi-Paxos replica system to handle more complex scenarios involving multiple replicas. This system employed the PMMC (Paxos Made Moderately Complex) design, integrating:
- Two-Phase Commit: To coordinate transactions across multiple nodes, ensuring all or none of the operations are committed.
- Two-Phase Locking: To manage concurrent access to resources, preventing conflicts and ensuring data consistency.
- Paxos Replica Groups: To achieve consensus among replicas, allowing the system to function correctly even if some replicas fail.
This combination enabled the creation of a sharded KV-store system with properties similar to Google's Spanner, providing scalability and strong consistency across distributed nodes.
Implementation Details
Two-Phase Commit (2PC)
To coordinate transactions across multiple nodes, ensuring all or none of the operations are committed.
Introduction and Explanation:
The Two-Phase Commit (2PC) protocol is a distributed algorithm that ensures all participating nodes in a distributed transaction agree on a common commit or abort decision. It is widely used in distributed database systems and transaction processing systems to maintain atomicity and consistency across multiple nodes or databases.
Phases of Two-Phase Commit:
- Prepare Phase (Voting Phase):
- Initiation: The coordinator (transaction manager) initiates the commit process by sending a
PREPARErequest to all participating nodes (participants). - Local Transaction Execution: Each participant performs all necessary operations associated with the transaction but does not commit them. This stage ensures that the transaction is ready to be committed.
- Vote Collection: Participants respond to the coordinator with a vote:
VOTE_COMMIT: If the participant's local operations are successful and it is ready to commit.VOTE_ABORT: If the participant encounters any issues that prevent it from committing.
- Initiation: The coordinator (transaction manager) initiates the commit process by sending a
- Commit Phase (Decision Phase):
- Decision Making: The coordinator collects all votes from participants.
- Global Commit: If all participants vote
VOTE_COMMIT, the coordinator decides to commit the transaction. - Global Abort: If any participant votes
VOTE_ABORT, the coordinator decides to abort the transaction.
- Global Commit: If all participants vote
- Notification: The coordinator sends a
GLOBAL_COMMITorGLOBAL_ABORTmessage to all participants based on the decision. - Finalization: Participants act on the coordinator's decision:
- Commit: If the decision is
GLOBAL_COMMIT, participants commit their local transactions. - Rollback: If the decision is
GLOBAL_ABORT, participants rollback any changes made during the transaction.
- Commit: If the decision is
- Decision Making: The coordinator collects all votes from participants.
Key Features:
- Atomicity: Ensures that all nodes commit or none do, maintaining data integrity.
- Reliability: Handles failures by allowing participants to recover and reach a consistent state.
- Coordination: Centralizes decision-making through a coordinator, simplifying the commit process.
Potential Issues:
- Blocking Protocol: If the coordinator fails during the commit phase, participants may become blocked, waiting indefinitely.
- Single Point of Failure: The coordinator's failure can halt the entire transaction process.
- Overhead: Increased message passing and logging can impact system performance.
Two-Phase Locking (2PL)
To manage concurrent access to resources, preventing conflicts and ensuring data consistency.
Introduction and Explanation:
Two-Phase Locking (2PL) is a concurrency control method used in database systems to ensure serializability, which means transactions are executed in a manner equivalent to some serial execution. It achieves this by controlling how transactions acquire and release locks on data items.
Phases of Two-Phase Locking:
- Growing Phase:
- Lock Acquisition: A transaction may acquire locks on data items it needs.
- No Lock Release: During this phase, the transaction does not release any locks.
- Purpose: Ensures that once a transaction starts acquiring locks, it continues to do so until it reaches its peak resource usage.
- Shrinking Phase:
- Lock Release: The transaction starts releasing the locks it holds.
- No New Locks: No new locks can be acquired during this phase.
- Purpose: Guarantees that after a transaction starts releasing locks, it cannot acquire any more, preventing cyclic dependencies.
Types of Locks:
- Exclusive Lock (Write Lock): Allows a transaction to both read and modify a data item. No other transaction can acquire any lock on that item.
- Shared Lock (Read Lock): Allows a transaction to read a data item. Other transactions can also acquire a shared lock on the same item but cannot write to it.
Key Features:
- Serializability: Ensures that concurrent transactions produce the same result as if they were executed serially.
- Strict 2PL Variant: A stricter version where all exclusive locks are held until the transaction commits or aborts, preventing cascading aborts.
Potential Issues:
- Deadlock Possibility: Transactions may become deadlocked if each waits for locks held by the other.
- Reduced Concurrency: Overly restrictive locking can limit parallelism, affecting system throughput.
- Complexity: Managing locks and detecting deadlocks adds complexity to the system.
Paxos Replica Groups
To achieve consensus among replicas, allowing the system to function correctly even if some replicas fail.
Introduction and Explanation:
Paxos is a family of consensus algorithms designed to achieve agreement on a single value among distributed systems or replicas, even in the presence of failures. It ensures that a network of unreliable processors can agree on a value, making it fundamental for building fault-tolerant distributed systems.
Roles in Paxos:
- Proposers:
- Function: Suggest values to be agreed upon.
- Responsibility: Initiate the consensus process by proposing values to acceptors.
- Acceptors:
- Function: Decide which proposed value to accept.
- Responsibility: Participate in voting and ensure that once a value is chosen, it remains consistent.
- Learners:
- Function: Learn the final agreed-upon value.
- Responsibility: Update their state based on the outcome of the consensus process.
Phases of Paxos:
- Phase 1: Prepare Phase
- Proposal Number Generation: The proposer generates a unique proposal number
n. - Prepare Request: The proposer sends a
Prepare(n)message to a majority of acceptors. - Promise Response: Acceptors respond with a
Promise(n, accepted_n, accepted_value)ifnis greater than any previous proposal number they have seen.- No Further Acceptances: Acceptors promise not to accept any proposals numbered less than
n.
- No Further Acceptances: Acceptors promise not to accept any proposals numbered less than
- Proposal Number Generation: The proposer generates a unique proposal number
- Phase 2: Accept Phase
- Proposal Value Selection: The proposer selects the value with the highest accepted proposal number from the acceptors' responses; if none, it can use its own value.
- Accept Request: The proposer sends an
Accept(n, value)message to the acceptors. - Acceptance: Acceptors accept the proposal if
nmatches their promised proposal number and persist the accepted value. - Learning the Value: Acceptors inform learners about the accepted value, completing the consensus process.
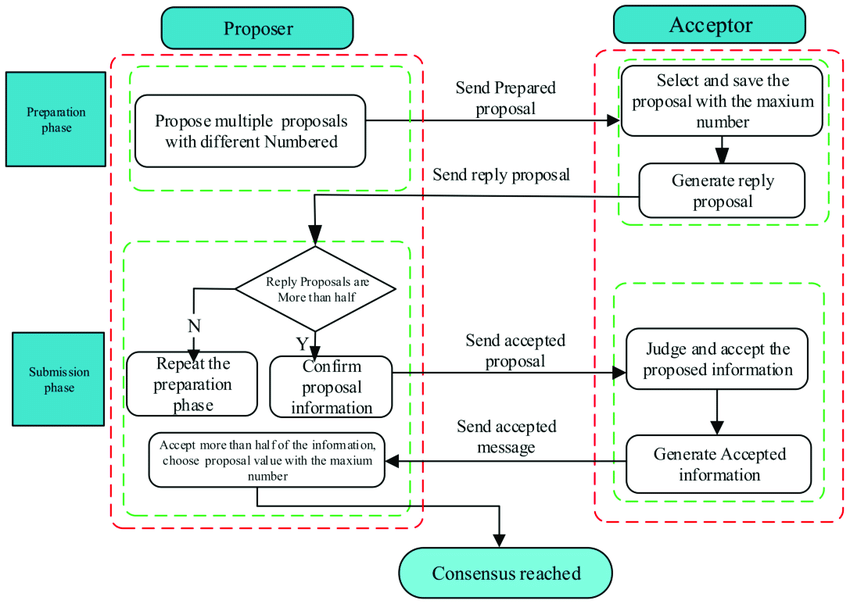
Key Features:
- Fault Tolerance: Can tolerate failures of some acceptors as long as a majority can communicate.
- Consistency: Ensures that all non-faulty processes agree on the same value.
- Asynchronous Operation: Does not rely on synchronized clocks or timing assumptions.
- Safety Over Liveness: Prioritizes correctness even if progress (liveness) is temporarily hindered.
Potential Issues:
- Complexity: The algorithm is intricate, which can make implementation challenging.
- Performance Overhead: Multiple rounds of communication can impact performance in high-latency networks.
- Progress Under Failures: While safety is guaranteed, liveness can be affected if proposers continually fail.
Applications:
- Distributed Databases: Ensures consistency across database replicas.
- Distributed File Systems: Maintains file system metadata consistency.
- Coordination Services: Underpins services like Google's Chubby and Apache ZooKeeper.
Sharding with Paxos and Atomic Multi-Key Transactions
To add sharding of the key-value store across server groups (each of which implements Paxos), with dynamic load balancing and atomic (transactional) multi-key updates across server groups.
Introduction and Explanation:
Sharding is a database architecture pattern that partitions data across multiple servers, allowing the system to scale horizontally and handle increased load. In this context, sharding the key-value store distributes the data and workload across multiple server groups. Each server group manages a subset of the data (a shard) and uses Paxos to maintain consistency within the group.
The addition of dynamic load balancing and atomic multi-key updates introduces complexity, as transactions may span multiple shards. Implementing these features requires careful coordination to ensure data consistency and system reliability.
Implementation Details:
- Data Sharding Across Server Groups:
- Partitioning Strategy:
- Hash-Based Sharding: Use a consistent hashing function to map keys to specific shards. This method evenly distributes data and simplifies the addition or removal of shards with minimal data reshuffling.
- Range-Based Sharding: Assign contiguous key ranges to different shards. While efficient for range queries, it may require more complex load balancing to prevent hotspots.
- Shard Mapping:
- Maintain a global shard map that keeps track of which keys or key ranges belong to which shards.
- The shard map should be replicated across all nodes and clients to ensure consistent routing of requests.
- Partitioning Strategy:
- Server Groups Implementing Paxos:
- Replica Management:
- Each shard is managed by a server group comprising multiple replicas.
- Paxos is used within each group to achieve consensus on updates, ensuring consistency even if some replicas fail.
- Leader Election:
- Paxos facilitates leader election within each server group. The leader handles client requests and coordinates updates, improving efficiency.
- Fault Tolerance:
- The system tolerates failures as long as a majority of replicas within a group are operational.
- Replica Management:
- Dynamic Load Balancing:
- Monitoring Load Metrics:
- Continuously monitor each shard's load based on metrics like request rate, latency, and resource utilization.
- Rebalancing Mechanisms:
- Shard Splitting: When a shard becomes overloaded, split it into smaller shards and redistribute the data across new server groups.
- Shard Merging: Underutilized shards can be merged to optimize resource usage.
- Data Migration:
- Migrate data between shards carefully to maintain consistency.
- Use Paxos to coordinate data movement, ensuring that all replicas agree on the migration process.
- Updating the Shard Map:
- Atomically update the shard map during rebalancing to prevent inconsistencies.
- Clients and server groups should be notified of shard map changes promptly.
- Monitoring Load Metrics:
- Atomic Multi-Key Updates Across Shards:
- Distributed Transactions:
- Implement transactions that can span multiple shards while ensuring atomicity and consistency.
- Transactions must be coordinated to either fully commit or fully abort across all involved shards.
- Two-Phase Commit Protocol Across Shards:
- Phase 1 (Prepare):
- A transaction coordinator sends a prepare request to all shards involved in the transaction.
- Each shard executes the transaction locally and votes to commit or abort.
- Phase 2 (Commit/Abort):
- If all shards vote to commit, the coordinator sends a commit message; otherwise, it sends an abort message.
- Shards finalize the transaction based on the coordinator's decision.
- Phase 1 (Prepare):
- Concurrency Control:
- Two-Phase Locking (2PL):
- Transactions acquire locks on required keys during the growing phase.
- Locks are held until the transaction commits or aborts, preventing other transactions from conflicting.
- Deadlock Detection:
- Implement mechanisms to detect and resolve deadlocks that may occur due to distributed locking.
- Two-Phase Locking (2PL):
- Distributed Transactions:
- Client Interaction and Request Routing:
- Shard Map Utilization:
- Clients use the shard map to determine the appropriate shard for each key.
- For multi-key transactions, the client interacts with a transaction coordinator that manages communication with all relevant shards.
- Handling Shard Map Changes:
- Clients must handle updates to the shard map gracefully, possibly by fetching the latest version upon receiving a notification or encountering a routing error.
- Shard Map Utilization:
- System Components:
- Transaction Coordinator:
- Manages distributed transactions across multiple shards.
- Ensures atomicity by coordinating the two-phase commit process.
- Shard Manager:
- Oversees shard creation, splitting, merging, and deletion.
- Maintains the shard map and handles its distribution to clients and server groups.
- Load Balancer:
- Monitors system performance and triggers rebalancing actions when necessary.
- Works closely with the shard manager to redistribute data.
- Logging and Recovery:
- Implement logging mechanisms to record transaction states and shard configurations.
- Facilitate recovery procedures in case of failures or crashes.
- Transaction Coordinator:
Key Considerations:
- Consistency Models:
- Decide between strong consistency and eventual consistency based on application requirements.
- Strong consistency ensures immediate visibility of writes but may impact performance.
- Eventual consistency allows for higher availability and performance at the cost of temporary inconsistencies.
- Scalability:
- Design the system to scale horizontally by adding more server groups as data volume and traffic increase.
- Ensure that the addition of new shards and server groups does not disrupt existing operations.
- Fault Tolerance and High Availability:
- Utilize replication and consensus algorithms (like Paxos) within server groups to handle server failures.
- Implement failover mechanisms for transaction coordinators and shard managers.
- Performance Optimization:
- Minimize cross-shard transactions when possible, as they introduce overhead.
- Cache shard map information on clients to reduce lookup latency.
- Security and Access Control:
- Implement authentication and authorization mechanisms to protect data.
- Ensure secure communication channels between clients and servers.
Challenges and Learnings
Developing this system presented several challenges:
- Concurrency Control: Implementing two-phase locking required careful handling of deadlocks and ensuring that locks were acquired and released in a manner that maintained system performance and consistency.
- Consensus Protocols: Integrating Paxos into the system necessitated a deep understanding of consensus algorithms and their practical implementation challenges, such as dealing with network partitions and ensuring liveness.
- Fault Tolerance: Ensuring the system could recover gracefully from various failure scenarios involved rigorous testing and validation of the replication and recovery mechanisms.
Through this project, I gained hands-on experience with the complexities of building distributed systems, particularly in achieving fault tolerance and consistency in a sharded environment.
Conclusion
The development of a fault-tolerant, sharded KV storage system in CSE 452 provided invaluable insights into the design and implementation of distributed systems. By integrating exactly-once RPC mechanisms, primary-backup architectures with Viewstamped Replication, and multi-Paxos replica systems, I was able to create a robust and scalable storage solution. This experience has deepened my understanding of distributed consensus, fault tolerance, and the practical challenges of building reliable distributed applications.